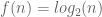Oh C, the good old language which is still out there, and on which many newer languages are based. It’s common for people to think that C isn’t for the faint of heart, but the language is actually simple. So simple that it’s almost never the best choice for a large project which isn’t an operating system. Here I’ll not introduce C, or how to program using C. I’ll assume that you have some knowledge of the language, and will discuss how I like to use C by addressing common beginner mistakes and general stylistic preferences.
Good Code
I, to this day, still believe that ‘Good Code = Good Types + Good Functions’. Let’s think about it, the types you define (structs) and the types you define a more representative or simpler alias for (typedefs), constitute the data the program will hold. The functions are the operations to be applied on those types. And that’s it, define your types and write proper operations and you’re good to go.
Good Functions
Before talking about types, let’s first talk about functions. Here’s the biggest mistake: long functions. While dealing with C, you’re most likely on your own, with nothing to help you but a debugger, a profiler, and function documentation at your disposal. So connecting to a server and receiving a chunk of data from it, in my mind, was a simple task that should be one function. I started going back and forth between my code and the documentations, stacking lines over lines in the same scope. In the end it worked, but it looked terrible. I moved on to the next task and repeated the same thing.
Some guidelines to write good functions:
- Small: Consider each sub-task a task on its own, and write it as such. In fact, every ((sub-sub)^n)-task should be written independently.
- Meaningful return: Return something, let it be an error, a state, or otherwise. Use ‘void’ only for a procedure routine; that’s something that just defines a certain flow of operations and that’s it.
- Stateless: Try as much as possible to avoid reading variables which aren’t part of your function arguments.
- Pointer-free: Do you really need a pointer for this? probably not. If you do, think again before passing it. You should avoid manipulating passed arguments, which means that you probably shouldn’t use a pointer for this.
- Callbacks: C supports higher-order functions, USE THAT! Don’t go too far or you’ll end up in callback hell and hate yourself (learn from your JavaScript experience).
Let’s discuss the guidelines a bit.
‘Small’, classic and everyone will tell you that all the time but hold on a second. By ‘small’ I mean really really small. I usually start from the function which represents the final goal, then I start going down as if it was a tree and everything I think of under it is a new function, apply recursively until you’ve hit rock bottom.
‘Meaningful return’. Man oh man. Just return something useful, damn it! Tell me how things went, give me a modified version of an argument instead of changing its value and let me decide what to do with it. Remove ‘void’ from your dictionary, you’ll know when you really need to use it when you start not using it all.
‘Stateless’. Everyone in the programming scene will tell you so, do as they say.
‘Pointer-free’. But that’s C, we have to use pointers. Do we really? You have the power to do something but that doesn’t mean that you should use it. Problems with pointers arise because of the abuse of pointers. Use them wisely and be considerate when you ask for a pointer instead of an object.
‘Callbacks’. Callbacks are fine, yeah they’re function calls and the compiler will not know how to inline them (I guess! Haven’t checked actually) but they are good way to chain operations together. Use them when you can. And since function pointers can get ugly, we’ll see how to deal with that in Good Types.
Good Types
There’s not much to say here, write good descriptive types which fit the purpose of your program or library. Define enums instead of passing integer if your values are categorical. Define typedefs for function pointers you want to use as callbacks and give them good names. Use typedefs to make a more meaningful alias of a generic type. And for the love of anything you hold sacred, define structs with typedefs.
Coding Convention
100% of experienced programmers will tell you that having a code convention for yourself and for a team is fundamental. Pick the one you’re most comfortable with and go for it. I personally prefer CamelCase for types (enums and structs) even when most C code bases use snake_case for them. I hate having ‘struct <type>’, use typedef struct instead. I also like snake_case for functions, leaving a space between a keywork or a function name and the parentheses (except for function calls). And if you follow the concept of making your functions small, you can easily encapsulate other coding conventions within the functions themselves, and hide them.
Taking this a bit further, I consider coding principles part of the convention. There are no restrictions here, whatever principal design you like to follow in the way you code, just follow it.
Heap Allocation
Two comments here: reduce allocations, profile your memory usage. Unless needed, use the stack memory instead, but the moment you start having heap allocation is the moment you use something like Valgrind to validate that you’re not messing anything up.
Ugly but Performs Well
In most cases you should favor good design and stylistic decisions over better performance. The reason is simple, don’t use relative performance comparison, use an ultimate set one and see if you hit or not. Instead of saying this piece of code is 25% faster, decide how much throughput, and as long as you’re satisfying that limit, relative performance within that range is meaningless. Oh, and did I mention profiling? STOP MAKING GUESSES, use a profiler, micro-benchmark (if needed), use Godbolt to see the compiler output of some pieces of code. When you’re done with that then decide if you want better performance or not.
Be Ready for Optimization
Yeah you don’t usually need to optimize, but what if you had to? Learn how to optimize the performance of your code, learn how to deal with bottlenecks. Just be ready so that when the moment comes, you don’t spend days learning first.
That’s it, that’s my philosophy while using C. I follow the same philosophy with other languages as well, but I’m not as pedantic with them.