This is the second installment of a series of posts I’m writing about how we developed iArabicWeb16 search engine. In the previous post, we talked about the overall architecture, and went through some design decisions. In this post, we’ll focus on how we indexed the 150M documents.
Documents Format and Processing
Before jumping into the process of indexing, we need first to understand how the crawled data was represented. It was a collection of WARC files (know more about them here). Now from the WARC files we needed to extract few things: the title, the URL, the type of the document, and the content. Luckily, the collection was split into multiple WARC files which made it easier to parallelize and/or distribute the indexing step.
Indexing Process
Indexing documents in Lucene is as easy as it gets, so we won’t talk about it. Instead, we’ll talk about the process itself. The indexing process was three-fold: partitioning, indexing, and merging. The following figure shows those steps.
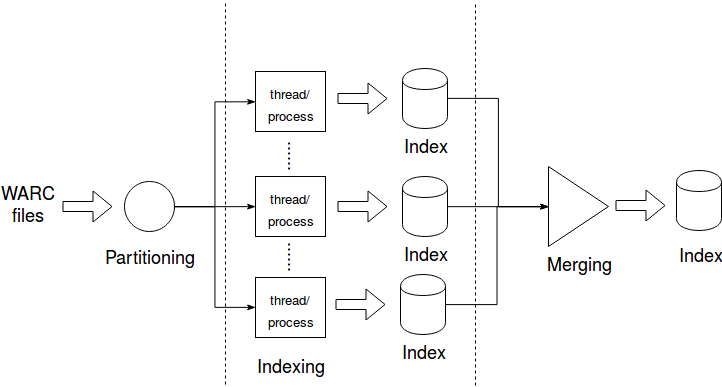
-
Partitioning
Since we had a lot of documents, indexing them in one shot would take a very long time. Instead, we partitioned the dataset into nearly identical partitions and gave each one to an indexer. Now we have two options: multiple threads on the same machine, or multiple processes across different machines. In the early days we had only one machine, but after we acquired three decent machines for the research group we distributed the process. This was done over a year ago and I don’t have the exact numbers, but indexing across multiple machines was MUCH faster, as one would expect.
-
Indexing
Now that we are done with partitioning the data, we can go on and build our individual indexes. The indexer itself has knowledge of neither the partitioner nor the merger; it operates independently.
You might have noticed in the figure that we said “thread/process”, this conveys two ways of operating. The first is using threads, and it is made for the cases where everything is small enough to fit into a single machine. This was the case in the beginning where we had fewer files for experimentation. After we were done with the tests and experiments on the data, we had to index everything, and that’s when the second mode of operation came into play. Luckily for us, the machines had access to a shared Network File System, so we didn’t have to transfer some of the files over from one machine to another.
If you have done some work with Lucene you might be wondering why I didn’t mention the number of segments or the merging policy. That’s because at this stage, we don’t know how many segments we need. We will discuss this in the merging step.
-
Merging
So far so good, we have N indexes ready to be searched. Not so fast. Our requirements state that there will only be one searcher. Not distributed search engine; the machines we had access to are not only for this project after all.
Now we have another problem, how many segments should the final index contain? Let me tell you why this is a problem. You can search multiple segments in parallel, but you cannot search a single segment in parallel, unless you are very careful and I am not sure if Lucene’s index structure will even allow it. Basically, too few segments and a single query will be slow, too many and you will have either 1) too many threads being slow because of context switching among them, 2) limited number of threads searching a large number of segments which will make it also slow. There is no way to find that sweet spot between the two extremes without experimentation.
That was pretty much all for this part. Unfortunately, our experiments and tests on indexing were not recorded, but expect some charts in the next one where we talk about searching.
