Two years ago, I started working on building a search engine for a web collection for Arabic web pages and tweets called ArabicWeb16. The collection contained around 150M web documents, and a lot of tweets (I don’t really remember the number). The project was quite challenging, especially for an undergraduate who hasn’t worked with such amount of data before and had to work on everything on his own. In this post, and the ones to come, I’ll go into the development process of the search engine and some of the decisions I made along the way.
Note: Some of the information mentioned here are discussed in a paper which was accepted into OSACT 2018.
The Requirements of the System
The requirements were very straightforward, here they’re:
- It should be able to index WARC files
- Indexing should be configurable and should have an option for parallel indexing
- The searcher should have an API for external use
- The searcher should allow retrieval of cached documents (i.e. the documents shouldn’t just be indexed, they have to be stored somewhere)
Tools, Languages, and Frameworks
Just like any other projects, some decisions regarding what will be used for the development process had to be made upfront. Here we’re going to go over some of the decisions related to that.
Java and Lucene
Although other options exist (such as Indri or Terrier), the obvious choice for any custom search engine is definitely Lucene with Java (or any other JVM language really). I could have used something like Solr as well to make my life easier, but I went with vanilla Lucene for the experience.
MongoDB
We need to store raw documents, sure we can store the content of documents in the index but there are multiple reasons why you probably shouldn’t do that, those reasons will be discussed in the posts to come. In the end, I settled for MongoDB, it’s convenient, fast, and fits the problem perfectly. If we wanted to store relations between documents as in constructing a web graph, the better option would have been Neo4j but we had no need for that.
Play Framework
Since we wanted to provide a search API, I needed a web framework to build a REST API, and for that I chose Play. Play comes packed with features that make developing web back-end an easy experience. It also supports concurrency, and is highly configurable.
NodeJS
Why do we need two web servers? Simple, one for the web interface and one for the search API. Why not mix the two together? check the next section for an answer. Why NodeJS? it’s easy, lightweight, and super fast to build a web back-end with. Of course you can easily write a messy server code with it since it’s JavaScript, but I shamefully did in some parts. I had to refactor many parts of the code later after I was more experienced with JavaScript.
Search Architecture
In this section we’ll discuss the architecture of the system without indexing; details on the indexing phase will be discussed in the next post.
We mentioned some technologies in the previous sections but we didn’t mention how they all fit together. This figure will show how the all interact with one another.
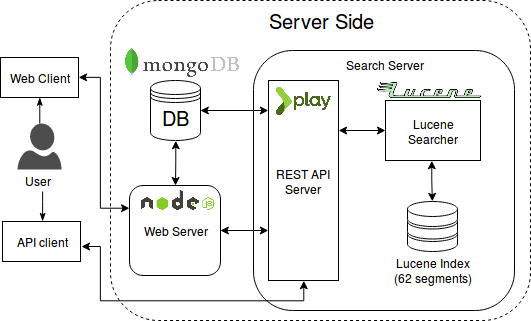
As you can see, a user can either search using the web interface, or using the REST API (of course a key needs to be acquired before having access to the REST API server).
So why do we have two web servers? If the world of software engineering has taught us one thing it’s got to be that coupling is bad, and in our case, here’s precisely why:
- What happens if we wanted to deploy each one on a different machine? We can’t
- What happens if we wanted to modify one of them? We have to shut down everything and redeploy
- The most important point, what happens if we wanted to distribute the index and have multiple search servers, one for each? Again we can’t do that if we’ll put everything into one piece
- The web server takes care of rendering web pages but it also manages users, sessions, and provides access to a topic collection tool (only visible to certain users). None of that has anything to do with searching the collection. It only makes sense that we have a separate server which takes care of those things
That’s all for this part, in the next post we’ll talk more about indexing the collection.

